Description
What is Travel Booking Portal?
A Travel Booking Portals is a website that allows customers and travel agents to book flights, hotels, holiday packages, and other services online. It provides an online platform for the travel industry to set up their business on the web with a few features and modules. In travel the online business modules there are two business modules:
-
APIs Active Portal
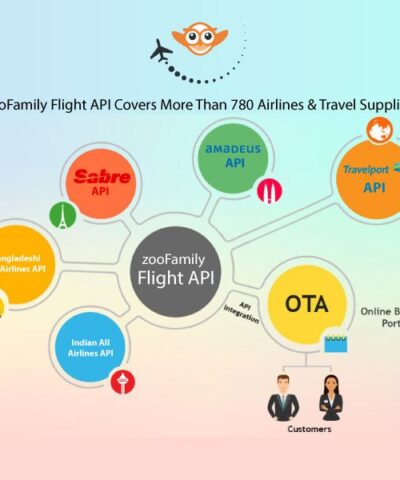
If you want to make an APIs functional website then we will create an APIs active system. where you can activate your hotel booking APIs. And with that API you can receive live inventory data. And a user can book a room or flight from the system. The investor company can choose the API supplier for their OTA (Online Travel Agency). Our Flight and Hotel solution are APIs active portal where you will get APIs booking system.
-
Upload Active Portal
Upload active portal is a functional website where from the admin panel the admin can upload products like tours, visa assistance, or other services. By uploading from the admin panel the inventory will be live. And from the website and a user can book the inventory or service. Our tour and visa solution is an upload active portal where you will get an uploading travel booking system.
What is OTA Software?
OTA means Online Travel Agency. In short, OTA software is an online travel booking system software. An OTA software is very expensive to build. So it’s better if you work with any travel technology company. Because travel technology company has the work experience to work with travel solutions. Here are our travel portal solutions:
We have 3 packages for your OTA development. To know more, click our packages:
Zoo Travel Technology is a certified GDS API developer where we are working with flight booking portals, Hotel booking portals, Tour DMC booking portals, And visa support portals. All category is a solution of travel technology, where flight & hotel solutions are connected with APIs. Tour & Visa portals are upload system solutions. We developed the whole system with the PHP Laravel system, and we maintain the full system with a high-security could server.

If you don’t understand the business module then you need an online travel booking portal consultant. Our consultant will describe the full business module and plan.
Order Online Travel Booking Portal Consultancy
I will describe the online travel booking system and its API’s functionality. Describe how an admin panel works with the functionality and its features. And help you to choose the travel APIs for your online travel booking portal.

After Consultancy Scope of work:
- We will set up OTA Software on your domain.
- APIs Active System or Upload Active System
- Responsive layout with 100% mobile compatibility.
- Easy and User-Friendly UI.
- B2C & B2B Modules Active.
- Payment gateway integration.
- Real-Time Availability, Booking & Cancellation.
- Mark-up and Discount Management.
- Balance Management System.
- CRM data and Customer Management System.
- Agent Management System.
- Email & SMS Integration.
- Accounts Management System.
- Admin And Customer Dashboard.
- Coupon code features.
- Live Chat Integration.
- AIT TAX & Convenience Fee Features.
(Our Solutions are – Flight + Hotel + Tour + Visa Solutions)
Zoo Travel Technology Related product: Flight API | Hotel API
zooFamily Related product: Flight API | Hotel API